火车头采集器V9版使用Post方法采集Ajax页面
教程总目录:火车头采集器使用教程
前几天有个人进群问采集当当网的商品详细描述,我看到后没在群里说话直接开始研究了。还没研究好那人就退群了。。这两天研究另外一个教育类网站,网站列表页是通过POST方式加载的Ajax数据。下面给大家分享下火车头如何采集此类网站。
教程可能有一些长,写的详细了些,耐心看完你会看懂的。
教程采集网站:https://zikao.eol.cn/chengrenzikao/index.html
采集网站分析
采集任何一个新站前我们都要对他进行一番分析才好下手。下面写一下我对这个教育类网站的分析内容。
列表页分析
这个网站的列表页,前面并不是通过Ajax加载的。CTRL+U可以直接看到列表内容,通过浏览器也看不到相关请求地址。


因为习惯原因,我直接看了下尾页列表页。然后顺手CTRL+U看看网站代码结构有没有大的变化。防止后期采集出错。结果就发现无法看到列表内容。浏览器可以看到一个通过post请求的地址。
https://zikao.eol.cn/api/stl/actions/pagecontents
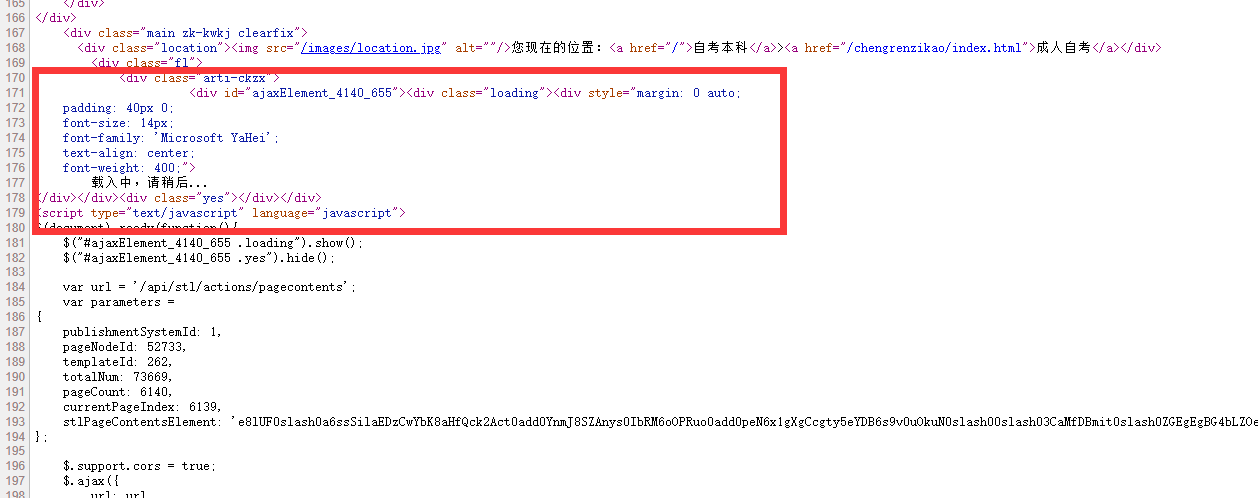
这时候就意识到这网站列表页可能后面的应该全是通过Ajax加载的。
通过笨方法,手动访问页面看看Ajax加载大概是哪些。最后找到大概从2200页左右开始Ajax加载。
那我们采集的时候,前面的列表页就可以使用普通方式去采集(速度更快)。
2200页开始到尾页就通过post请求Ajax页面数据。
抓包获取Post数据
https://zikao.eol.cn/api/stl/actions/pagecontents
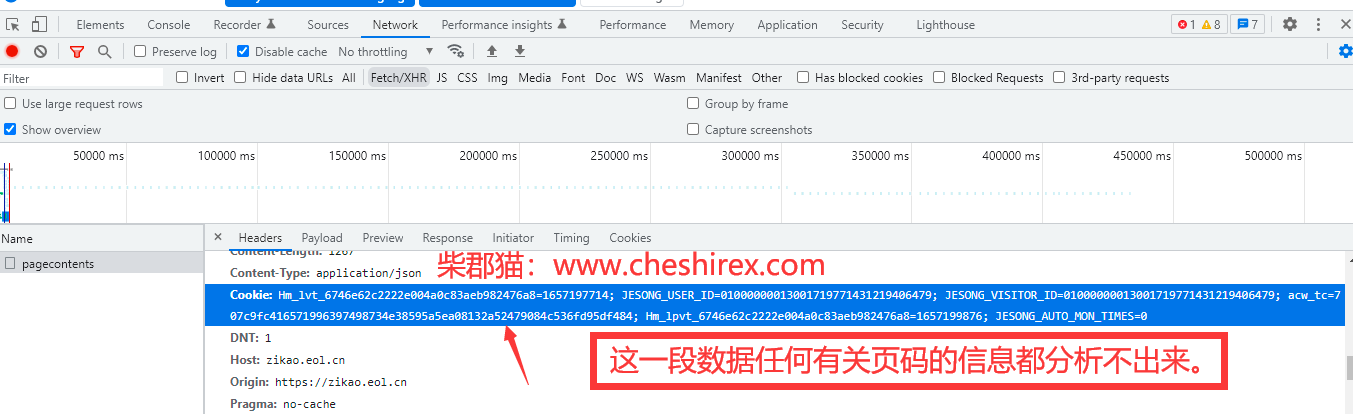
这个Ajax地址我在浏览器看不到任何跟页码有关的数据。最后只能使用抓包工具看一下详细的请求内容了。
安装设置抓包工具
抓包我们使用的Fiddler软件。
关于Fiddler的安装和设置查看这个文章:抓包工具Fiddler下载和设置
安装设置完成后我们打开浏览器。重新访问一下采集页面,Fiddler会抓到很多请求地址。
查看分析Post数据
Ctrl+F 我们搜索那个Ajax地址
https://zikao.eol.cn/api/stl/actions/pagecontents

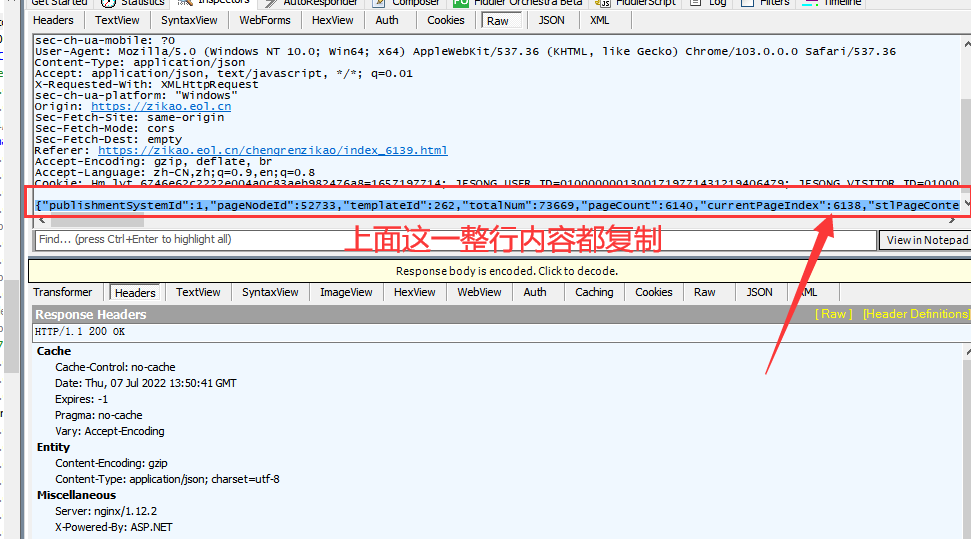
Fiddler会以黄色将搜索到的结果显示出来,我们点击一下他。
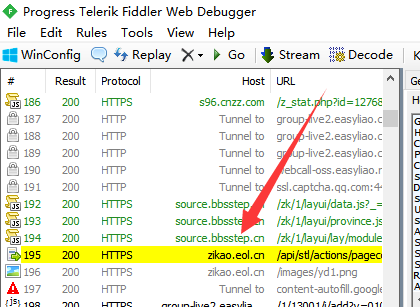
在Fiddler右侧会显示这个请求地址的相关详细信息。
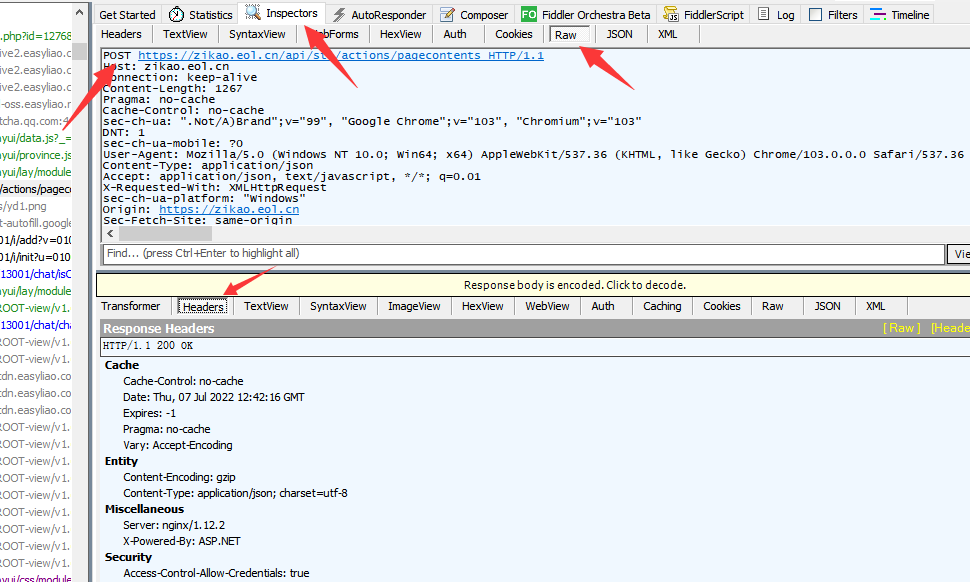
信息顶部可以看到是post请求方法。往下拉。
可以看到有我们请求的页码相关内容。
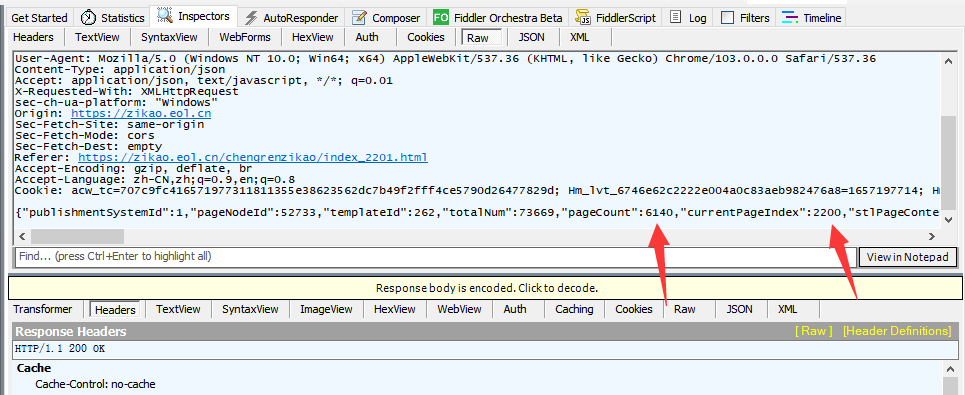
访问不同页码的页面,经过研究发现规律。
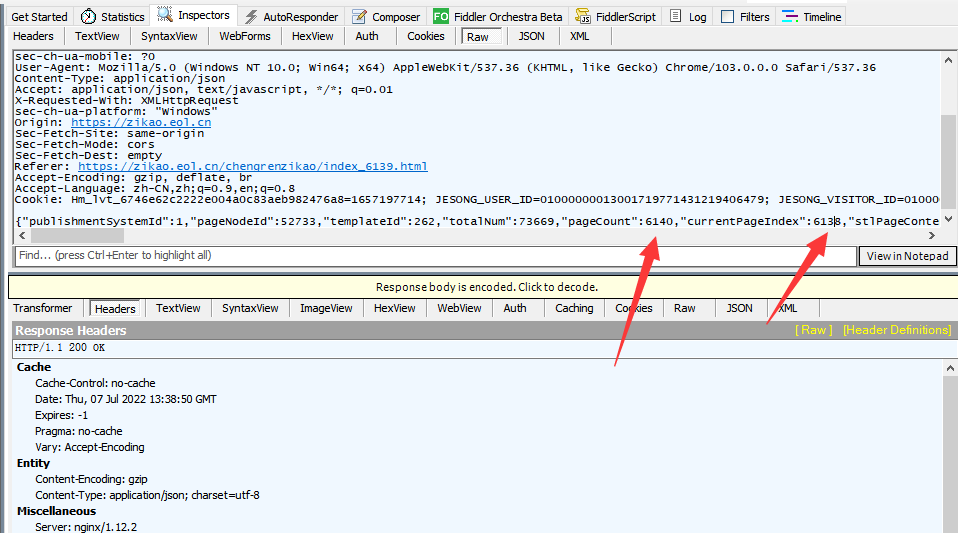
currentPageIndex的值和页码相关,值等于页码减一。我们访问6139页时,currentPageIndex值是6138。
这就找到了规律,我们打开火车头采集器。
设置火车头采集器
火车头分页设置
起始网址填入Ajax请求地址
https://zikao.eol.cn/api/stl/actions/pagecontents

点“高级模式”。
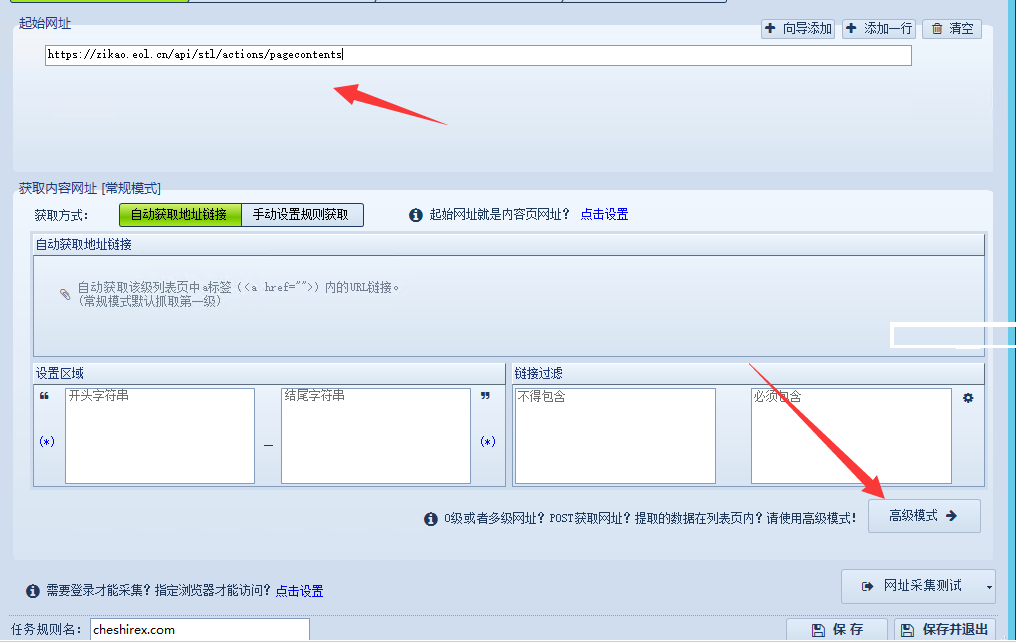
点“分页设置”,http请求方式“post”。
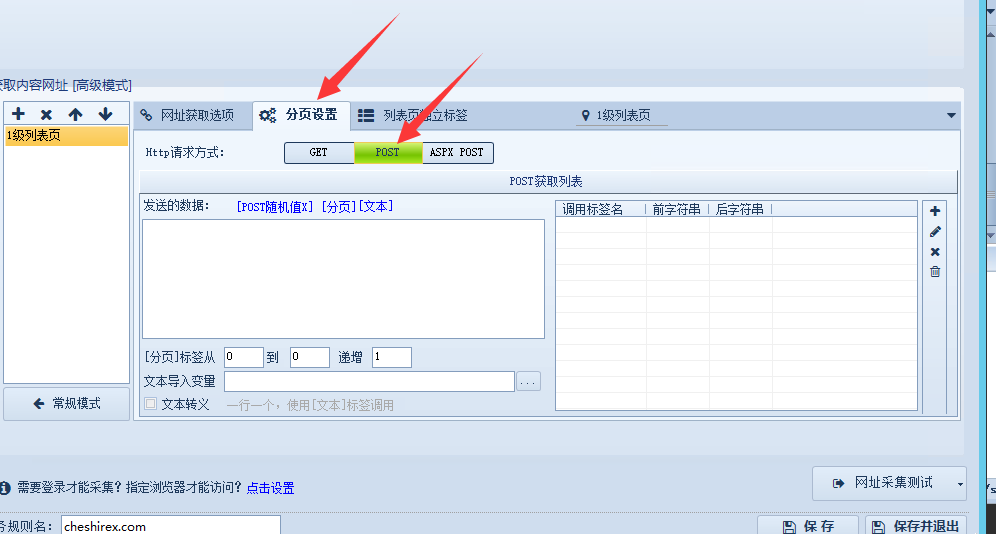
把我们Fiddler抓包获取的内容填进去。
将currentPageIndex值的内容替换成火车头采集器的“分页”标签。
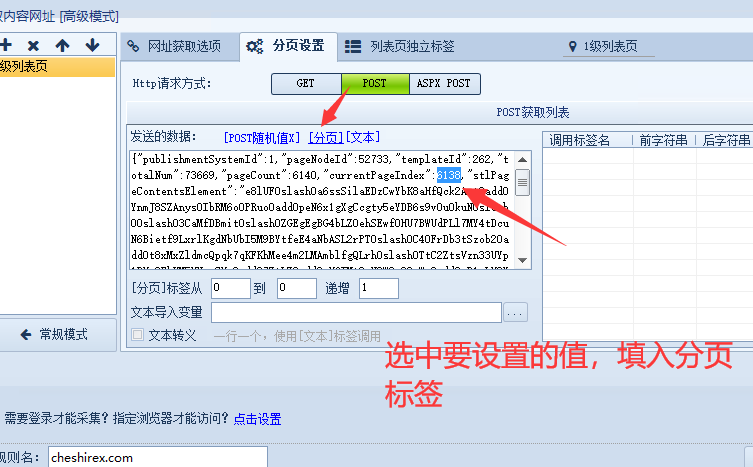
下面填入页码。
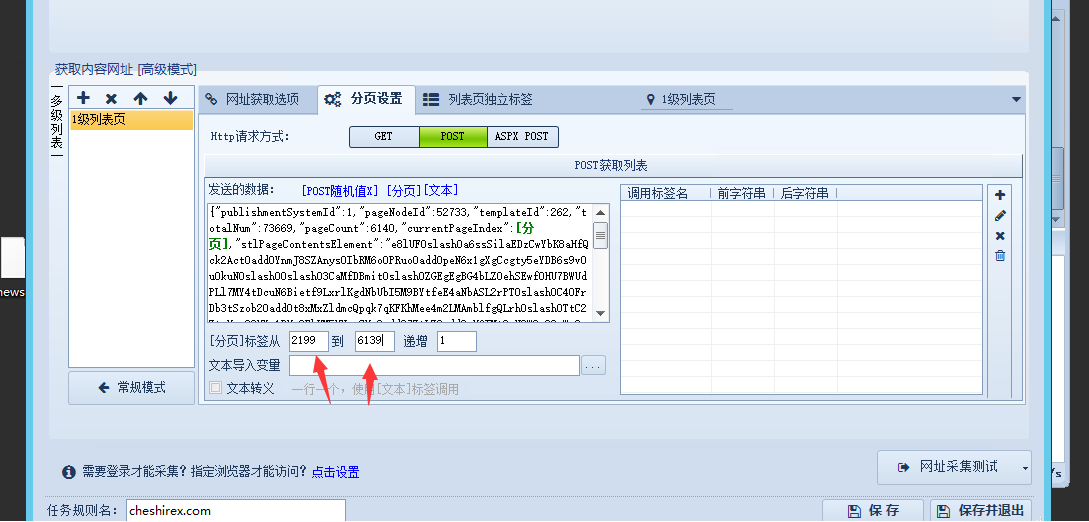
页面地址是从2200到6140,上面我们分析得出post请求内容的currentPageIndex值是实际页码减一。所以这里面我们填2199到6139.
网址获取选项设置
为了筛选出我们需要的内容,我们设置一下网址获取选项。
打开浏览器F12开发工具,预览一下Ajax获取的内容。
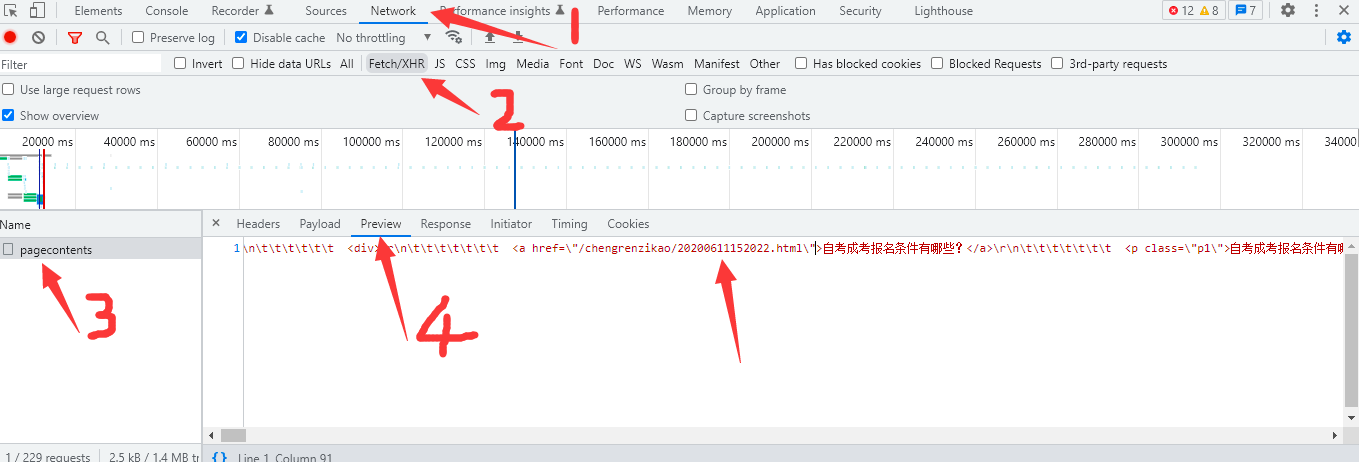
可以看到链接的形式是
<a href=\"/chengrenzikao/20200611152022.html\">自考成考报名条件有哪些?</a>
完整的链接地址是
https://zikao.eol.cn/chengrenzikao/20200611152022.html
那我们就可以使用下面的规则提取地址。
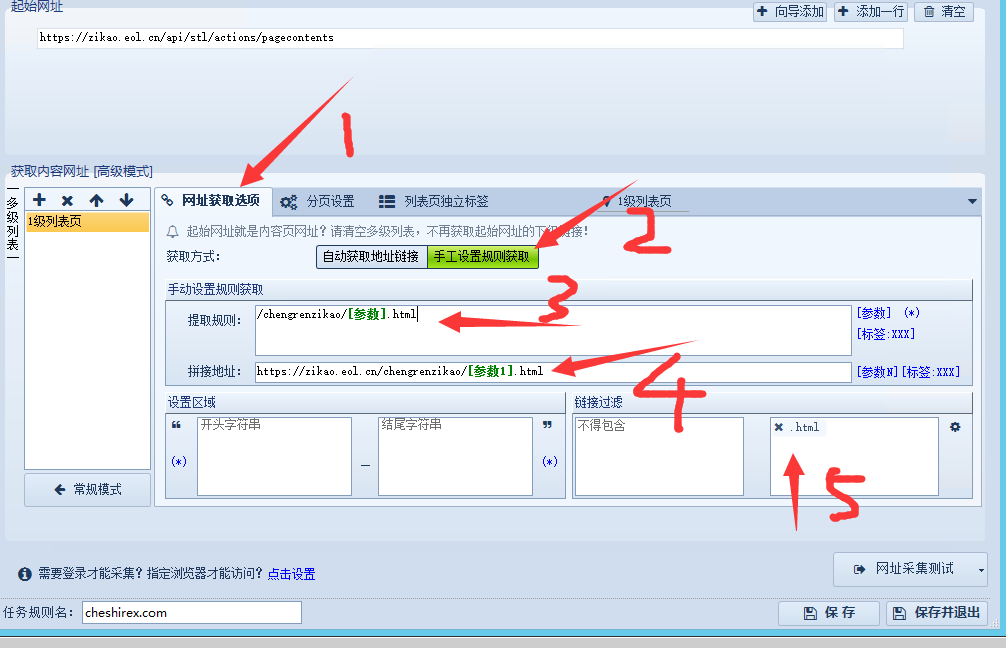
我们测试一下网址采集。
测试网址采集
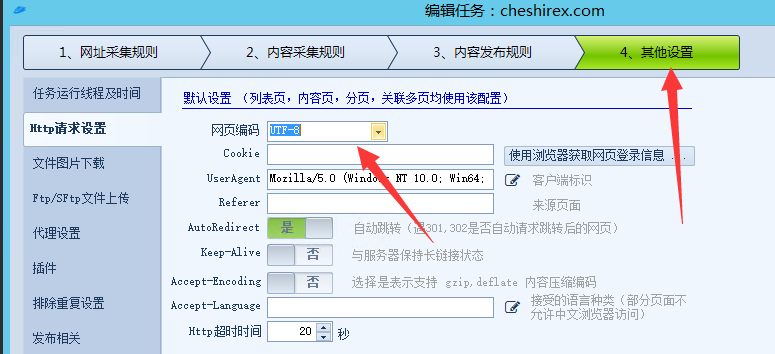
点击测试可能提示“post请求必须选择网页编码”我们在火车头其他设置中将编码选为“UTF8”即可。
可以看到已经正确获取到了链接。不放心可以复制链接实际访问一下看看是否正确。
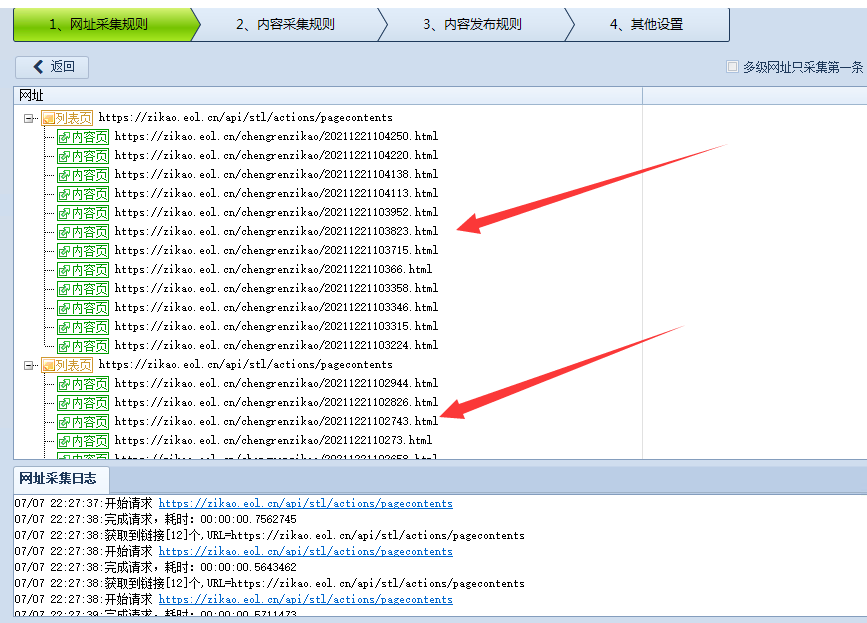
注意事项
采集过程注意运行线程和请求间隔时间。教程在测试时因为开的线程较多,频率过高导致对方网站开启了防CC设置。拉黑了我一个服务器IP,此教程写完用了两台服务器。
我们实际采集可以只开1个线程,并设置合适的间隔时间,比如1000ms到1500ms左右。
教程结束。
如果转载文章请带上本文地址。