火车头采集器使用教程–分析目标网站要采集内容的位置及规则
火车头采集器使用教程–分析目标网站要采集内容的位置及规则
教程总目录:火车头采集器使用教程
我们首先打开一篇文章,看看他的基本结构:标题和内容起始,以及是否有重复。
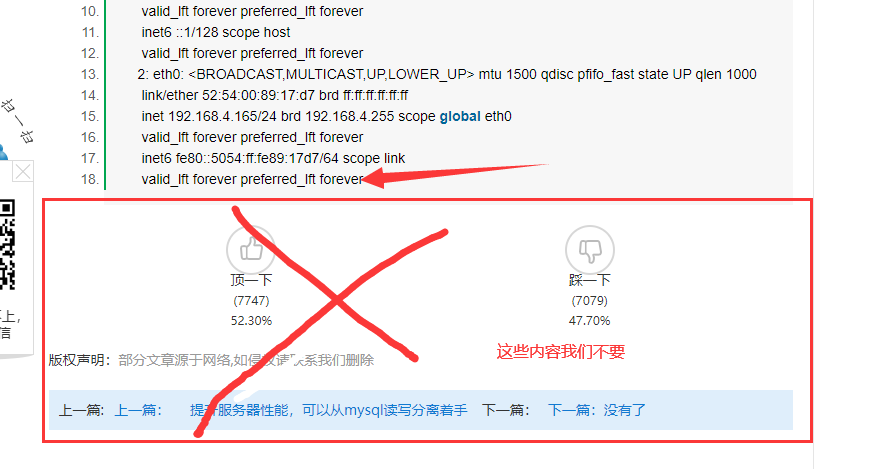
从下图可以看到有标题重复,以及我们不需要的内容(他的广告)
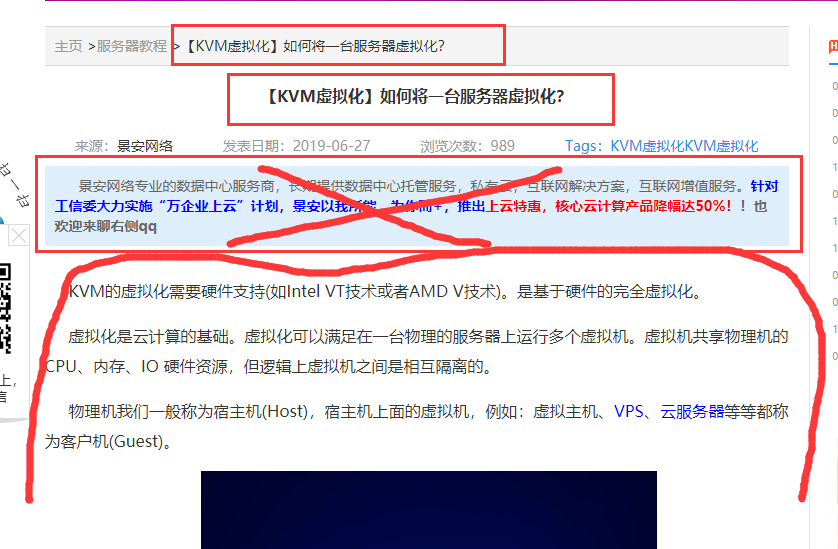
我们查看网页的源代码,CTRL+U
先搜索标题,看看标题都在哪些位置
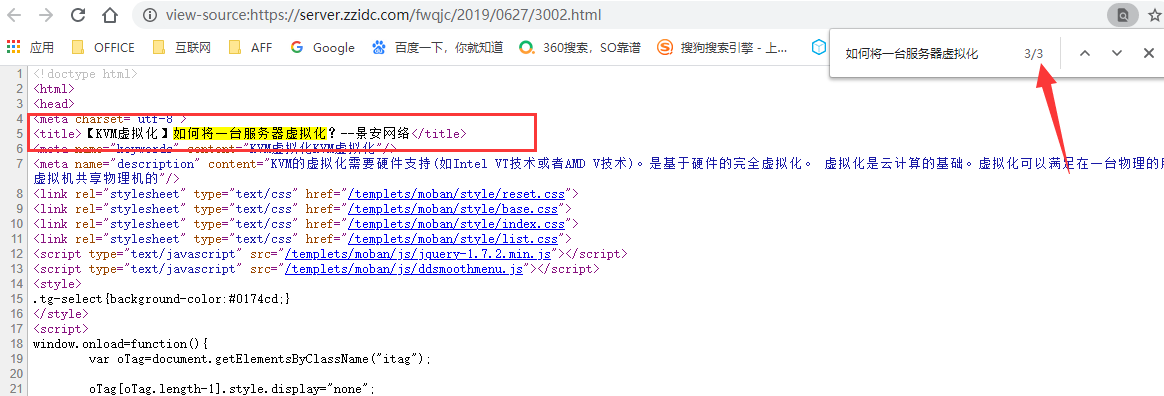

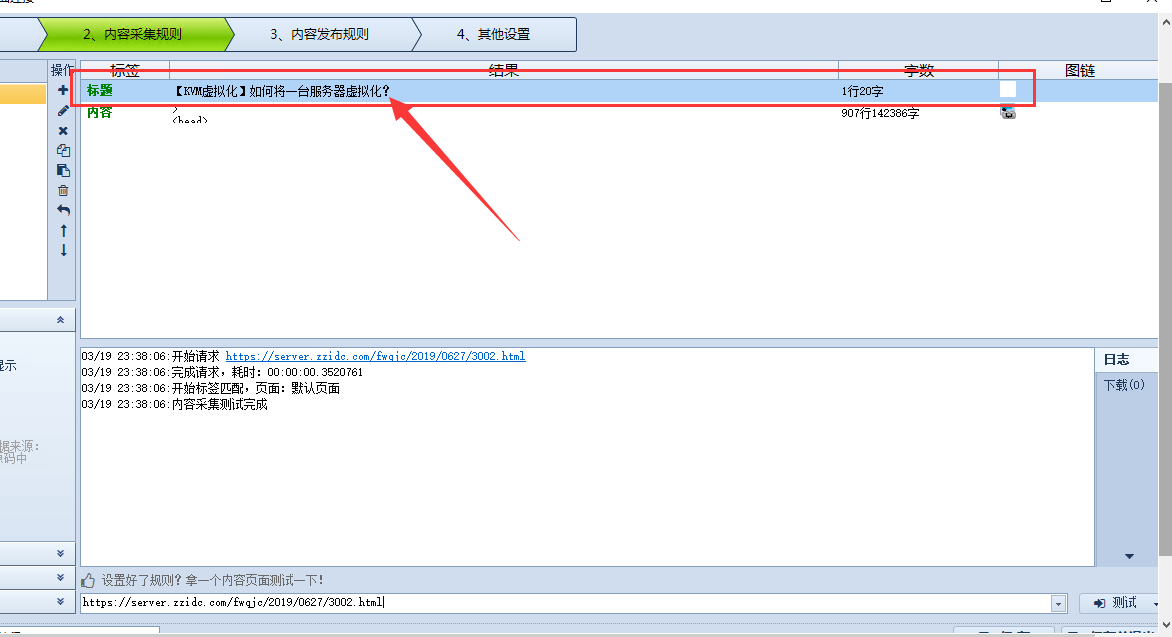
可以看到有三个位置都是标题,看到这三个位置,分析下前后的内容。最终我选择了第三个作为采集标题的位置。
因为前后和其他文章更不容易出现不同的情况。避免出现个别文章采集标题为空的情况。

我们打开火车头采集器
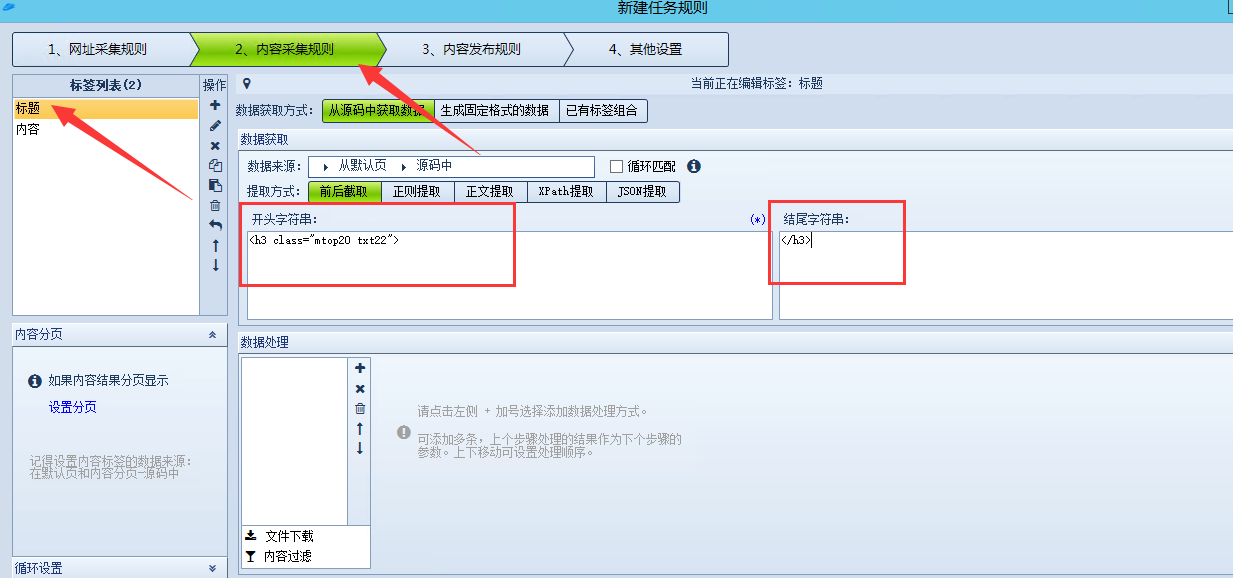
将<h3 class="mtop20 txt22″>作为标题的开头字符串
</h3>作为标题的结尾字符串
这两个字符串之间的内容,火车头会全采集下来,当做标题。所以不要选择错了
我们可以复制文章链接,在火车头里先测试下标题才是是否正确。
在下面有填测试连接的位置
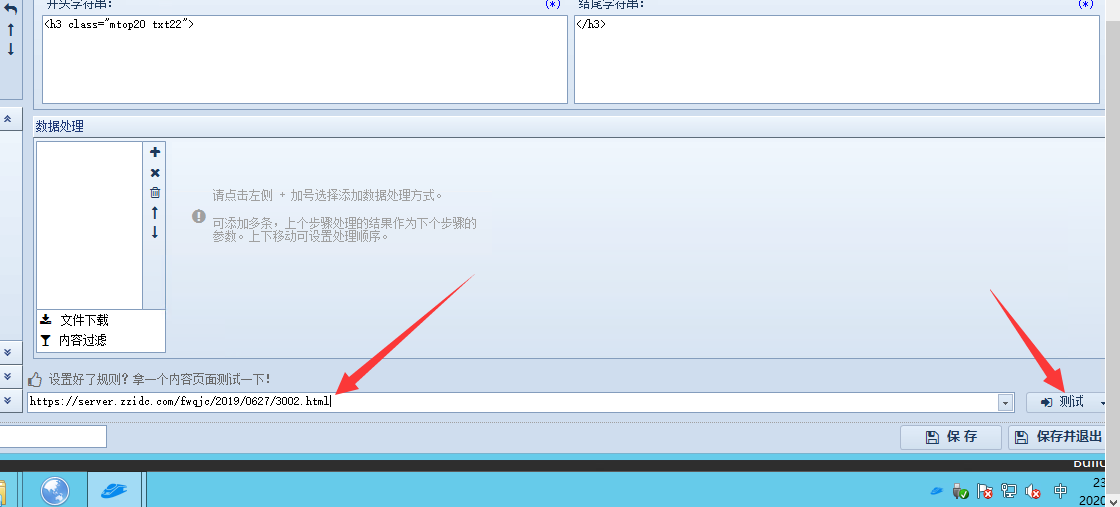
我们看到标题采集没问题
下面开始找内容的采集规则
在文章页面源代码里我们搜索内容前面几个字,发现有两个位置,一个是顶部的页面描述,一个是真正的正文开始位置。当然用下面这个啦

下面这个正文开始前的是他网站的广告,我们要在广告后面选取位置开始采集
记得那句话,火车头会从你选取的位置,采集下来里面所有的字符!所以位置要选对!
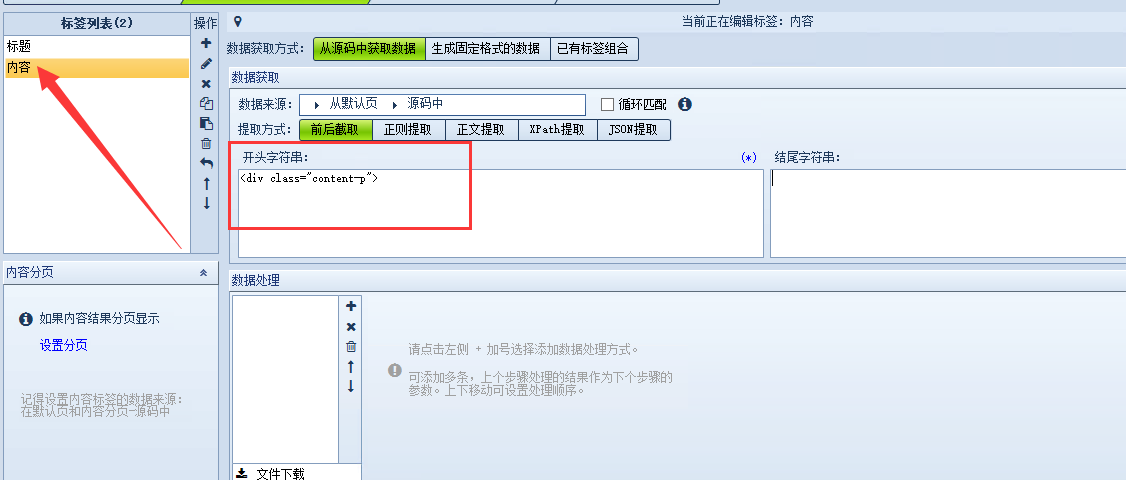
我们选择<div class="content-p">最为采集起始位置,这个正好也是实际正文内容的起始位置,并且在源码里搜索不到第二处!

将<div class="content-p">填入火车头正文采集规则的开头字符串
然后是正文结束的位置
正文在这里结束,因为结束正好是一段代码,所以看着可能比较乱。
请注意,搜索内容时,空格不要带,在源码里空格是其他的字符串,会出现搜索不到的情况。
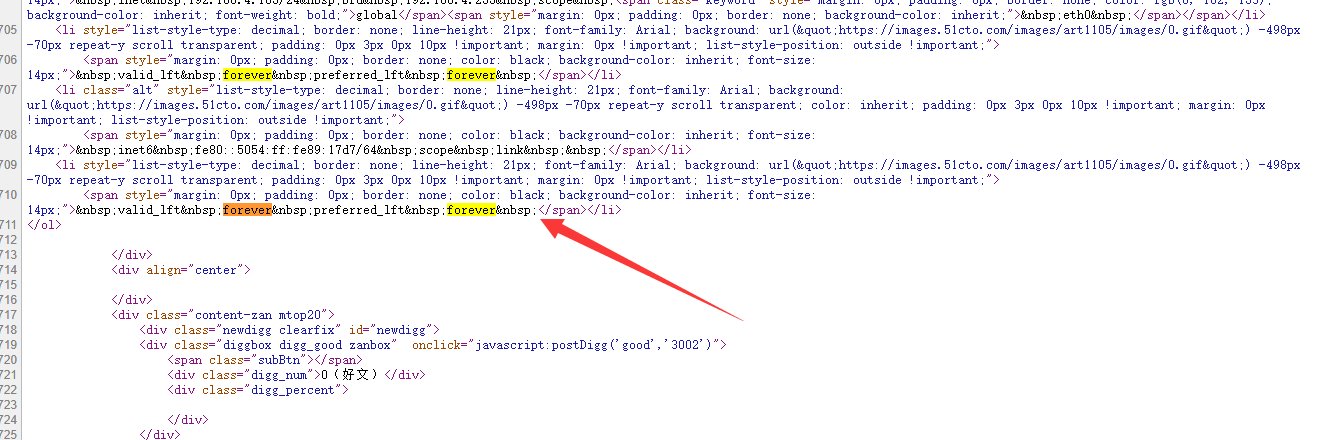
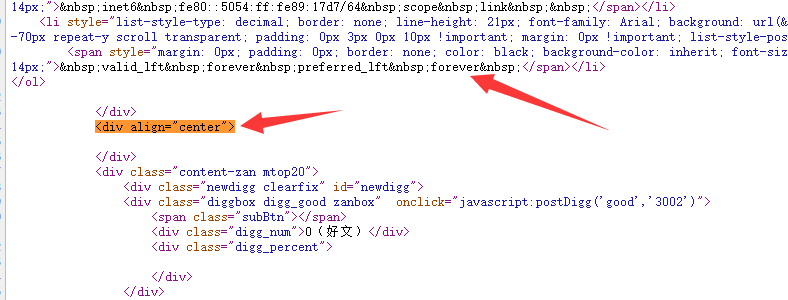
我们就选择正文结束后的<div align="center">作为火车头采集结尾字符串
这个字符串在源码里没有其他重复位置,并且是正文DIV结束后的第一个内容!
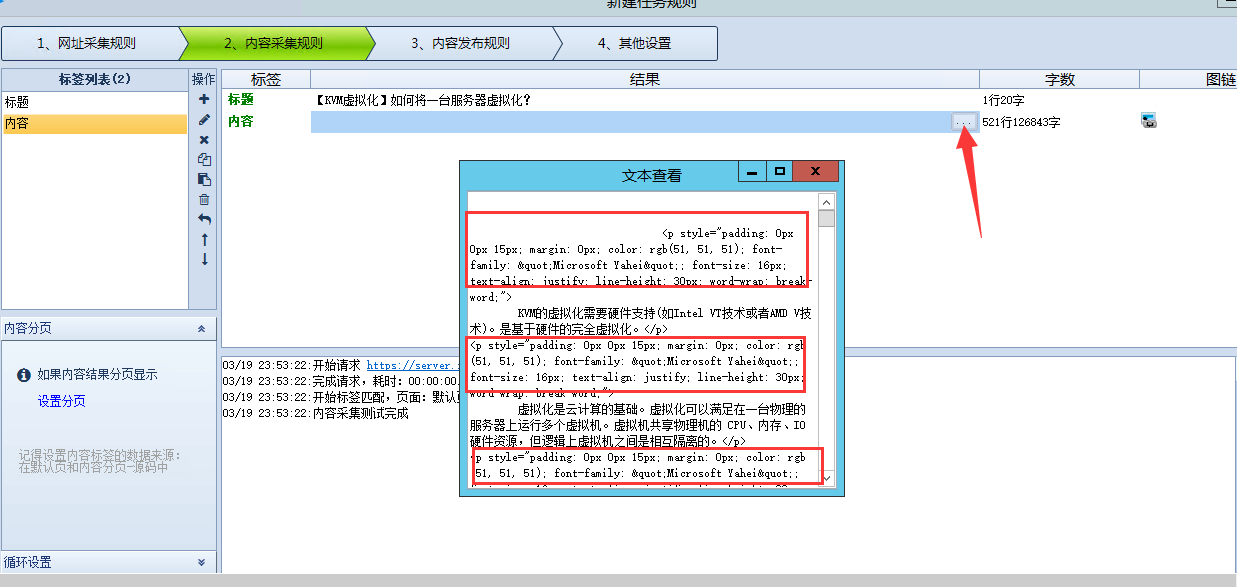
下面我们测试一下内容的采集,看看效果
然后会发现内容里有很多多余的字符样式之类。
查看内容可以点击内容后面的那个三个点,就可以出来个窗口查看了
我们需要对内容进行一下过滤
过滤掉不需要的字符
就是这个html标签过滤
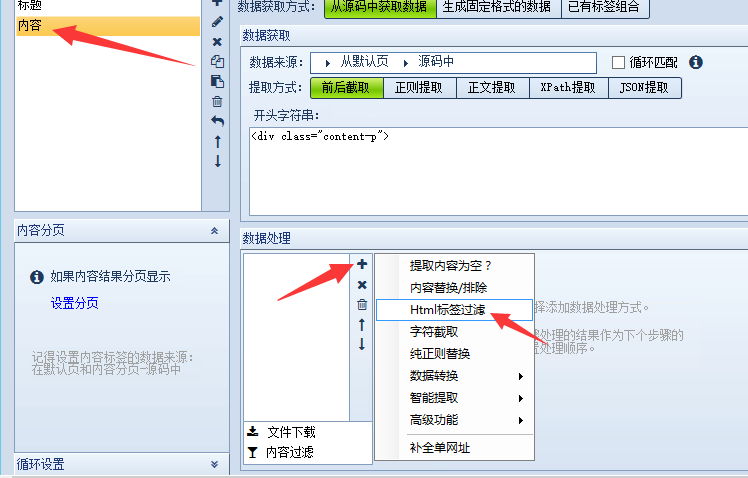
我们过滤掉:链接a标签、图像img标签、字体font标签、脚本script标签、层DIV标签、Span标签
具体需要过滤哪些,根据你采集的文章来决定,每个网站他发文习惯都不一样。
这里我过滤掉图片,并且没有做文件下载(图片下载)是因为图片下载,需要单独开一篇文章来写。
我们在测试一下看看采集内容的效果
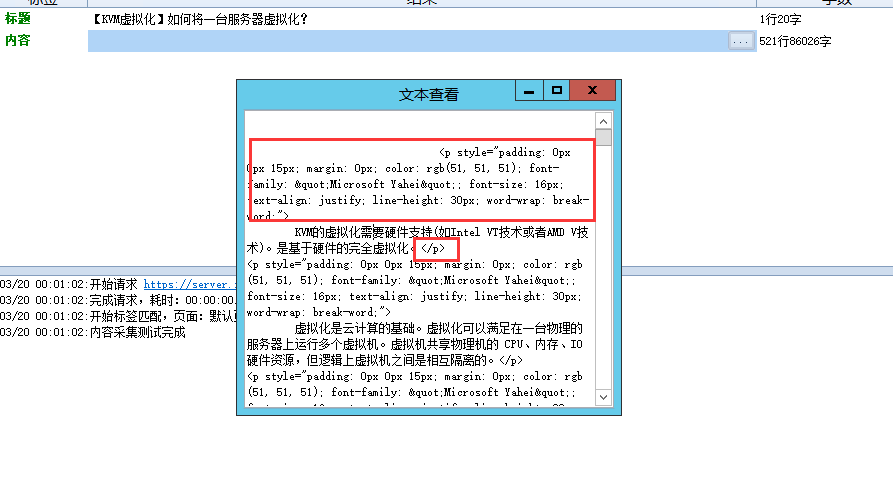
可以看到还是有字体相关的标签存在,但是他是以<p开头的,还负责文章的段落作用。这里就没办法通过火车头进行过滤了。不过也没啥影响。
到这里文章标题和正文内容的采集规则就结束了。后续内容请查看教程总目录
现在晚上12点了,停一下明天我再继续写。